GAN系列-03 Deep Convolutional Generative Adversarial Network
Deep Convolutional Generative Adversarial Network
前言
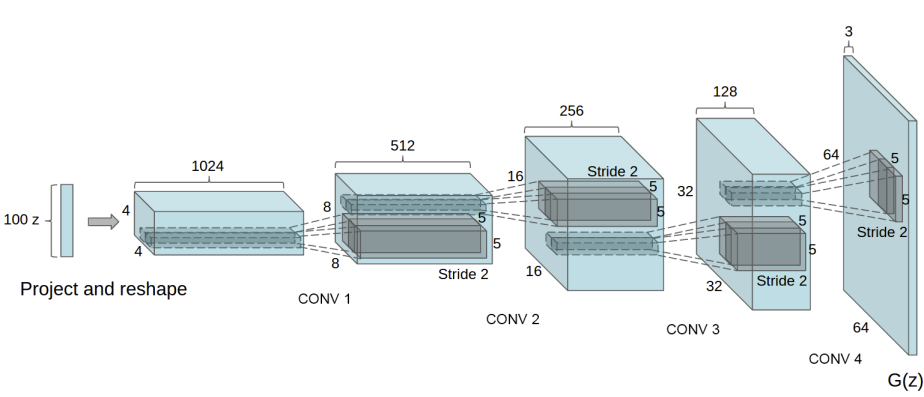
DCGAN這篇可以看成將GAN應用到CNN的論文,所使用的Objective Function跟GAN一樣,不同的地方在這篇論文的作者使用CNN跟Deconvolution(DeConv)來當訓練用的模型。在DCGAN中,Discriminator是一個CNN的網路,輸入一張圖片,然後輸出是真還假的機率;而Generator和CNN相反,輸入noise通過Generator生成一張圖片,因為vector通過一層層layer而逐漸變大,和CNN的作用相反所以稱之為DeConv。
DCGAN的特點
- 不使用pooling。Discriminator用帶有stride的Convolution Layer來取代Pooling;在Generator中使用Transposed Convolution Layer,而非UnPooling。
- 在Generator和Discriminator上都使用Batch Normalization。處理初始化不良導致的訓練問題,幫助梯度傳播到每一層,防止Generator把所有樣本都收斂到同一個點,用來穩定學習。
- 在模型中使用LeakyReLU當作activation function。
網路架構
參數宣告
可以看到除了必要儲存的檔案夾、參數以外,還多了一個TFRecordPath,這是因為在訓練之前會先將整個資料集轉換成TFRecord的形式,
1 | from absl import app |
資料集
在訓練過程中使用的是CelebA和MNIST資料集,CelebA根據圖片的類型共有3種不一樣的圖像資料分別為img_celeba、img_align_celeba、img_align_celeba_png,其中後兩個差異為儲存的檔案為jpg與png,此外img_celeba具有bbox的標籤,bbox會框出圖片中人臉的所在。
根據FLAGS.ImageType來決定需要讀入的為CelebA還是MNIST,從TFRecord檔案中讀入選擇的FLAGS.Partition資料,再透過tf.data.dataset來讀取資料、建構輸入資料的pipeline。
1 | def create_dataset(): |
Generator跟Discriminator的網路架構
因為所使用的資料集有彩色跟黑白的圖像,所以Discriminator在呼叫的時候需要加上Channel這個參數來調整輸入的維度:
1 | import tensorflow as tf |
Gen & Dis Net, Optimizer and Loss Function
可以看到這裡我們採用了PiecewiseConstantDecay的Learning Rate Schedule,分別在第10、20、25的epoch會下降:
1 | def setup_model(): |
Whole Training Process
整體的訓練過程因為可以透過傳遞參數訓練五種不同類型的圖像,所以架構上稍微複雜了一些:
1 | SaveName = '{}-{}'.format(FLAGS.ImageType, str(FLAGS.bbox)) |
Result
img_celeba with bbox
以下是使用img_celeba加上bbox資訊的訓練過程中每個Epoch的輸出:
img_celeba
這個則是直接使用img_celeba來訓練,其中每個Epoch的輸出,可以看到因為圖像保留的資訊較多(沒有擷取人臉的位置),所以生成圖片就顯得雜亂了許多,人臉部分生成的也不是很好:
img_align_celeba
使用img_align_celeba來訓練,其中每個Epoch的輸出,這是CelebA原本就提供的圖片,針對人臉的位置進行擷取,再做適當的padding:
MNIST
使用MNIST來訓練,其中每個Epoch的輸出,可以看到因為生成的圖片為64*64,所以圖片比起GAN較沒有顆粒感:
結論
DCGAN在論文中還分析了noise所在的潛在空間,透過兩個noise之間的點分析了這個潛在空間是否跟Word2Vec一樣具有意義,也針對生成圖片的noise進行加減,其中特別有趣的是:對戴墨鏡的男子-沒戴墨鏡的男子+女子的Vector,竟然可以得到戴墨鏡女子的圖片,這代表了這個潛在空間具有圖像的意義,令人大開眼界。
Github:GAN-03 Deep Convolutional Generative Adversarial Network
GAN系列-03 Deep Convolutional Generative Adversarial Network